 https://brightplanet.com/wp-content/uploads/2017/11/Screen-Shot-2017-11-01-at-1.51.04-PM.png
783
1154
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-05-24 12:47:412018-05-24 12:47:41AMPLYFI- Data and Beyond
https://brightplanet.com/wp-content/uploads/2017/11/Screen-Shot-2017-11-01-at-1.51.04-PM.png
783
1154
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-05-24 12:47:412018-05-24 12:47:41AMPLYFI- Data and BeyondDeep Web University Blog
https://brightplanet.com/wp-content/uploads/2017/11/Screen-Shot-2017-11-01-at-1.51.04-PM.png
783
1154
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-05-24 12:47:412018-05-24 12:47:41AMPLYFI- Data and Beyond https://brightplanet.com/wp-content/uploads/2015/09/mobile-phone-426559_1280.jpg
905
1280
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-05-10 15:16:502018-05-10 15:16:50Keeping up with the constantly changing Deep Web, BrightPlanet has developed the solutions that work
https://brightplanet.com/wp-content/uploads/2015/09/mobile-phone-426559_1280.jpg
905
1280
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-05-10 15:16:502018-05-10 15:16:50Keeping up with the constantly changing Deep Web, BrightPlanet has developed the solutions that work https://brightplanet.com/wp-content/uploads/2018/04/road-sign-63983_1920-1030x773.jpg
773
1030
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-04-20 07:56:222019-06-02 18:32:17All websites are not created equal. BrightPlanet knows how to harvest the exact data clients need, whether it is Deep Web, Dark Web or Surface Web content.
https://brightplanet.com/wp-content/uploads/2018/04/road-sign-63983_1920-1030x773.jpg
773
1030
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-04-20 07:56:222019-06-02 18:32:17All websites are not created equal. BrightPlanet knows how to harvest the exact data clients need, whether it is Deep Web, Dark Web or Surface Web content. https://brightplanet.com/wp-content/uploads/2016/08/telescope-187472_1280.jpg
960
1280
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-03-19 10:29:572018-03-19 10:29:57We harvest a lot of websites for our clients, but how do we know which sites to harvest in the first place?
https://brightplanet.com/wp-content/uploads/2016/08/telescope-187472_1280.jpg
960
1280
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-03-19 10:29:572018-03-19 10:29:57We harvest a lot of websites for our clients, but how do we know which sites to harvest in the first place?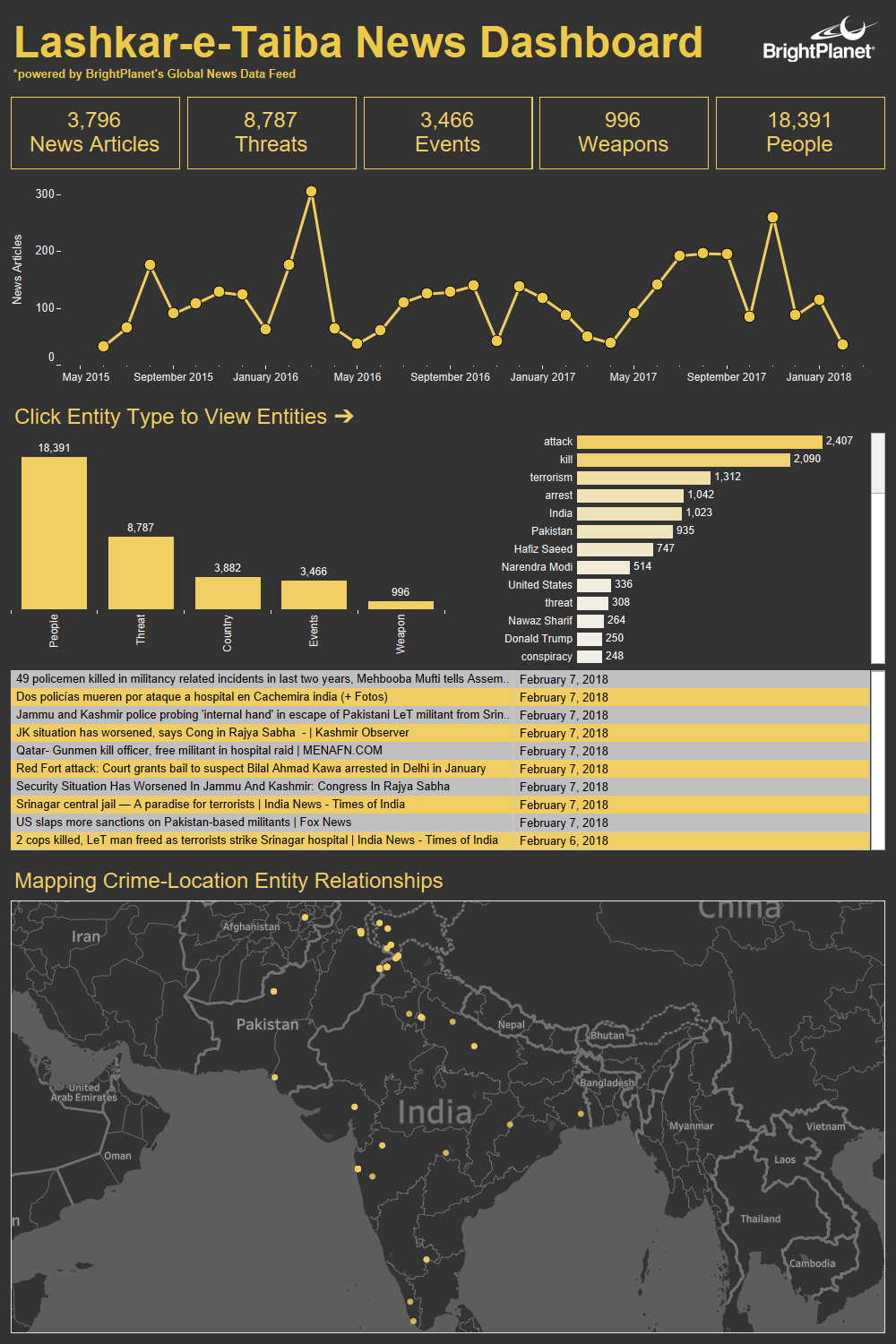 https://brightplanet.com/wp-content/uploads/2018/03/Lashkar-e-Taiba.png
1500
1000
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-03-05 09:31:332018-03-05 09:31:33Visualizing a Terror Group using Named Entity Tagging
https://brightplanet.com/wp-content/uploads/2018/03/Lashkar-e-Taiba.png
1500
1000
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-03-05 09:31:332018-03-05 09:31:33Visualizing a Terror Group using Named Entity Tagging https://brightplanet.com/wp-content/uploads/2017/12/Screen-Shot-2017-12-27-at-3.12.43-PM.png
454
1130
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-02-13 10:07:502018-02-13 10:07:50We talk a lot about Data-as-a-Service, but what exactly does that mean?
https://brightplanet.com/wp-content/uploads/2017/12/Screen-Shot-2017-12-27-at-3.12.43-PM.png
454
1130
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-02-13 10:07:502018-02-13 10:07:50We talk a lot about Data-as-a-Service, but what exactly does that mean? https://brightplanet.com/wp-content/uploads/2018/02/bitcoinImage.jpg
1271
1920
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-02-02 16:53:402018-02-02 16:53:40Mapping Bitcoin Metrics Across Deep Web News and Sentiment with Tableau
https://brightplanet.com/wp-content/uploads/2018/02/bitcoinImage.jpg
1271
1920
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-02-02 16:53:402018-02-02 16:53:40Mapping Bitcoin Metrics Across Deep Web News and Sentiment with Tableau https://brightplanet.com/wp-content/uploads/2018/01/Screen-Shot-2018-01-16-at-4.57.43-PM.png
618
930
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-01-17 20:02:402018-01-17 20:02:40Harvest Web Data in Multiple Languages with Unstructured Data Mining and Deep Web Search
https://brightplanet.com/wp-content/uploads/2018/01/Screen-Shot-2018-01-16-at-4.57.43-PM.png
618
930
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-01-17 20:02:402018-01-17 20:02:40Harvest Web Data in Multiple Languages with Unstructured Data Mining and Deep Web Search https://brightplanet.com/wp-content/uploads/2018/01/Screen-Shot-2018-01-09-at-3.32.21-PM.png
615
927
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-01-10 14:51:252018-01-10 14:51:25Artificial Intelligence and Unstructured Data Mining: Data Trends to Watch in 2018
https://brightplanet.com/wp-content/uploads/2018/01/Screen-Shot-2018-01-09-at-3.32.21-PM.png
615
927
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-01-10 14:51:252018-01-10 14:51:25Artificial Intelligence and Unstructured Data Mining: Data Trends to Watch in 2018 https://brightplanet.com/wp-content/uploads/2018/01/Screen-Shot-2018-01-04-at-11.50.51-AM.png
494
797
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-01-04 20:32:332018-01-04 20:32:33Stay Up to Date on All Things Deep Web: Subscribe to BrightPlanet's Deep Web University
https://brightplanet.com/wp-content/uploads/2017/12/Screen-Shot-2017-12-27-at-3.12.43-PM.png
454
1130
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-12-28 15:55:552017-12-28 15:55:55Webinar Recap: How to Turn Web Content into Usable Data for Data Analytics
https://brightplanet.com/wp-content/uploads/2018/01/Screen-Shot-2018-01-04-at-11.50.51-AM.png
494
797
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2018-01-04 20:32:332018-01-04 20:32:33Stay Up to Date on All Things Deep Web: Subscribe to BrightPlanet's Deep Web University
https://brightplanet.com/wp-content/uploads/2017/12/Screen-Shot-2017-12-27-at-3.12.43-PM.png
454
1130
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-12-28 15:55:552017-12-28 15:55:55Webinar Recap: How to Turn Web Content into Usable Data for Data Analytics https://brightplanet.com/wp-content/uploads/2017/12/erwan-hesry-126619-1.jpg
3114
6000
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-12-20 14:19:512017-12-20 14:19:51The Washington Post Reporter Uses AMPLYFI to Research North Korea
https://brightplanet.com/wp-content/uploads/2017/12/erwan-hesry-126619-1.jpg
3114
6000
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-12-20 14:19:512017-12-20 14:19:51The Washington Post Reporter Uses AMPLYFI to Research North Korea https://brightplanet.com/wp-content/uploads/2017/12/Screen-Shot-2017-12-13-at-12.58.44-PM.png
1012
1520
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-12-14 20:01:512017-12-14 20:01:51Combat Online Credit Card Fraud Through Dark Web Search and Open Source Intelligence Tools
https://brightplanet.com/wp-content/uploads/2017/12/Screen-Shot-2017-12-13-at-12.58.44-PM.png
1012
1520
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-12-14 20:01:512017-12-14 20:01:51Combat Online Credit Card Fraud Through Dark Web Search and Open Source Intelligence Tools https://brightplanet.com/wp-content/uploads/2017/12/Screen-Shot-2017-12-05-at-10.35.40-AM.png
497
747
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-12-05 19:59:132017-12-05 19:59:13Utilize OSINT Services for Better Fraud Prevention and Detection
https://brightplanet.com/wp-content/uploads/2017/12/Screen-Shot-2017-12-05-at-10.35.40-AM.png
497
747
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-12-05 19:59:132017-12-05 19:59:13Utilize OSINT Services for Better Fraud Prevention and Detection https://brightplanet.com/wp-content/uploads/2017/11/Screen-Shot-2017-11-29-at-3.53.52-PM.png
492
746
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-12-01 14:33:062017-12-01 14:33:06Differentiate the Deep Web and Dark Web with New Overview Resources
https://brightplanet.com/wp-content/uploads/2017/11/Screen-Shot-2017-11-29-at-3.53.52-PM.png
492
746
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-12-01 14:33:062017-12-01 14:33:06Differentiate the Deep Web and Dark Web with New Overview Resources https://brightplanet.com/wp-content/uploads/2017/11/Screen-Shot-2017-11-20-at-1.27.54-PM.png
1144
1834
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-11-21 15:13:072017-11-21 15:13:07Monitor the Future with Open Source Intelligence Tools Using Example Data from the Auto Industry
https://brightplanet.com/wp-content/uploads/2017/11/Screen-Shot-2017-11-20-at-1.27.54-PM.png
1144
1834
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-11-21 15:13:072017-11-21 15:13:07Monitor the Future with Open Source Intelligence Tools Using Example Data from the Auto Industry https://brightplanet.com/wp-content/uploads/2016/04/play-1073616_1280.png
1280
1280
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-11-14 15:30:012019-06-02 18:33:39VIDEO: Accessing the Dark Web with TOR Search on an Ubuntu Virtual Machine
https://brightplanet.com/wp-content/uploads/2016/04/play-1073616_1280.png
1280
1280
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-11-14 15:30:012019-06-02 18:33:39VIDEO: Accessing the Dark Web with TOR Search on an Ubuntu Virtual Machine https://brightplanet.com/wp-content/uploads/2017/11/Screen-Shot-2017-11-04-at-11.20.53-AM.png
778
1176
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-11-07 19:21:552017-11-07 19:21:55WEBINAR: How to Turn Web Content into Usable Data for Data Analytics
https://brightplanet.com/wp-content/uploads/2017/11/Screen-Shot-2017-11-04-at-11.20.53-AM.png
778
1176
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-11-07 19:21:552017-11-07 19:21:55WEBINAR: How to Turn Web Content into Usable Data for Data Analytics https://brightplanet.com/wp-content/uploads/2017/11/Screen-Shot-2017-11-01-at-1.28.06-PM.png
379
578
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
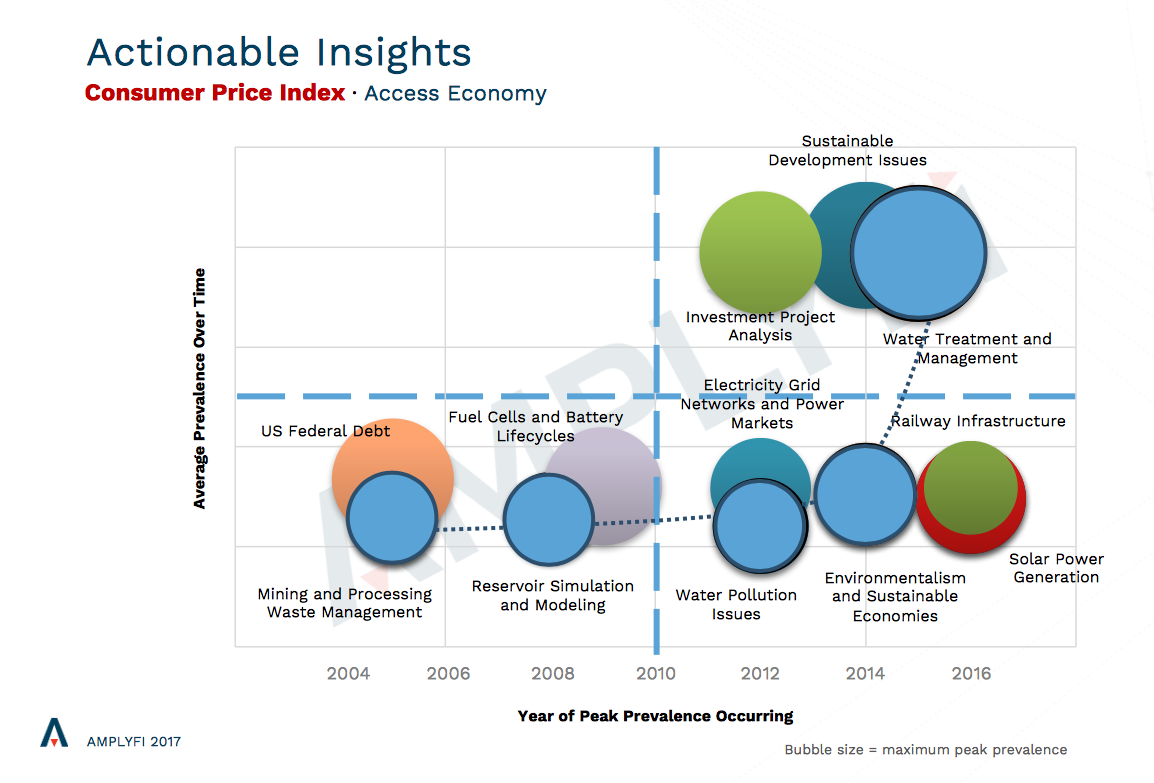
bluemonkeydev2017-11-03 16:41:152017-11-03 16:41:15Uncover Financial Trends Using Consumer Price Index and Access Economy Data Analysis
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-10-24 15:19:132017-10-24 15:19:13VIDEO: Installing TOR on an Ubuntu Virtual Machine
https://brightplanet.com/wp-content/uploads/2017/11/Screen-Shot-2017-11-01-at-1.28.06-PM.png
379
578
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-11-03 16:41:152017-11-03 16:41:15Uncover Financial Trends Using Consumer Price Index and Access Economy Data Analysis
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-10-24 15:19:132017-10-24 15:19:13VIDEO: Installing TOR on an Ubuntu Virtual Machine https://brightplanet.com/wp-content/uploads/2017/10/Screen-Shot-2017-10-16-at-1.42.57-PM.png
636
972
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-10-18 16:13:442017-10-18 16:13:44Breaking the I.T. Stereotype: How Speaking and Professionalism Can Grow Your I.T. Career
https://brightplanet.com/wp-content/uploads/2017/10/Screen-Shot-2017-10-16-at-1.42.57-PM.png
636
972
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-10-18 16:13:442017-10-18 16:13:44Breaking the I.T. Stereotype: How Speaking and Professionalism Can Grow Your I.T. Career https://brightplanet.com/wp-content/uploads/2017/10/Screen-Shot-2017-10-09-at-10.03.47-AM.png
227
523
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-10-10 16:17:142017-10-10 16:17:14Webinar Recap: Harvest Data While Understanding Complex Trends and Influencers with AMPLYFI
https://brightplanet.com/wp-content/uploads/2017/10/Screen-Shot-2017-10-09-at-10.03.47-AM.png
227
523
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-10-10 16:17:142017-10-10 16:17:14Webinar Recap: Harvest Data While Understanding Complex Trends and Influencers with AMPLYFI https://brightplanet.com/wp-content/uploads/2017/09/Ryan_Quam.jpg
2977
4465
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-10-03 20:20:302017-10-03 20:20:30Ryan Quam: BrightPlanet's Data Harvest Technology "Uber Geek"
https://brightplanet.com/wp-content/uploads/2017/09/Ryan_Quam.jpg
2977
4465
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-10-03 20:20:302017-10-03 20:20:30Ryan Quam: BrightPlanet's Data Harvest Technology "Uber Geek" https://brightplanet.com/wp-content/uploads/2017/09/Screen-Shot-2017-09-24-at-8.58.10-AM.png
164
810
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-09-26 17:22:562017-09-26 17:22:56Kalepa Adds BrightPlanet Data Feed to Data Solutions Marketplace
https://brightplanet.com/wp-content/uploads/2017/09/Screen-Shot-2017-09-24-at-8.58.10-AM.png
164
810
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-09-26 17:22:562017-09-26 17:22:56Kalepa Adds BrightPlanet Data Feed to Data Solutions Marketplace https://brightplanet.com/wp-content/uploads/2017/09/Screen-Shot-2017-09-20-at-9.11.38-AM.png
473
879
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-09-20 19:25:362017-09-20 19:25:36Learn About OSINT and Security Risk Management at ASIS 2017
https://brightplanet.com/wp-content/uploads/2017/09/Screen-Shot-2017-09-20-at-9.11.38-AM.png
473
879
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-09-20 19:25:362017-09-20 19:25:36Learn About OSINT and Security Risk Management at ASIS 2017 https://brightplanet.com/wp-content/uploads/2017/12/Screen-Shot-2017-12-13-at-12.51.36-PM.png
1008
1528
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-09-14 13:46:292019-06-02 18:35:24WEBINAR: Harvest Data While Understanding Complex Trends and Their Influencers with AMPLYFI
https://brightplanet.com/wp-content/uploads/2017/11/Screen-Shot-2017-11-29-at-3.53.52-PM.png
492
746
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-09-07 16:14:282019-06-02 18:44:15Greater Data Harvest Opportunities with the New Rosoka Update
https://brightplanet.com/wp-content/uploads/2017/12/Screen-Shot-2017-12-13-at-12.51.36-PM.png
1008
1528
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-09-14 13:46:292019-06-02 18:35:24WEBINAR: Harvest Data While Understanding Complex Trends and Their Influencers with AMPLYFI
https://brightplanet.com/wp-content/uploads/2017/11/Screen-Shot-2017-11-29-at-3.53.52-PM.png
492
746
bluemonkeydev
/wp-content/uploads/2016/05/BrightPlanet-site-logo-2-300x158.png
bluemonkeydev2017-09-07 16:14:282019-06-02 18:44:15Greater Data Harvest Opportunities with the New Rosoka UpdateWelcome to the Deep Web University
We coined the term “Deep Web,” and we talk about it – a lot.
Browse our articles, case studies and white papers to get the information you need to know about web data.
Have questions? Contact Us!